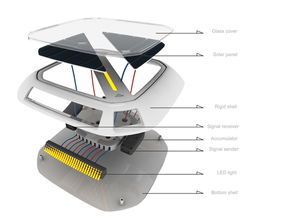
工業(yè)設(shè)計(jì)服務(wù) 連接創(chuàng)意與商業(yè)價(jià)值的專業(yè)橋梁

工業(yè)設(shè)計(jì)服務(wù)作為現(xiàn)代制造業(yè)和創(chuàng)新產(chǎn)業(yè)的核心環(huán)節(jié),正日益成為企業(yè)提升產(chǎn)品競(jìng)爭(zhēng)力、優(yōu)化用戶體驗(yàn)、實(shí)現(xiàn)品牌差異化的關(guān)鍵驅(qū)動(dòng)力。專業(yè)提供工業(yè)設(shè)計(jì)服務(wù)的公司,已不僅僅是傳統(tǒng)意義上的“美工”或“造型師”,而是整合了市場(chǎng)洞察、技術(shù)創(chuàng)新、工程實(shí)現(xiàn)與商業(yè)策略的多學(xué)科協(xié)作平臺(tái)。
1. 工業(yè)設(shè)計(jì)服務(wù)的核心價(jià)值
專業(yè)的工業(yè)設(shè)計(jì)服務(wù)公司,其核心價(jià)值在于將抽象的用戶需求與商業(yè)目標(biāo),轉(zhuǎn)化為具體、可行且富有吸引力的產(chǎn)品解決方案。這包括但不限于:
- 用戶體驗(yàn)研究(UX Research):通過用戶訪談、行為觀察、可用性測(cè)試等方法,深入理解目標(biāo)用戶的使用場(chǎng)景、痛點(diǎn)與潛在需求,為設(shè)計(jì)提供精準(zhǔn)的起點(diǎn)。
- 產(chǎn)品策略與定義:結(jié)合市場(chǎng)趨勢(shì)、技術(shù)可行性與商業(yè)目標(biāo),幫助客戶明確產(chǎn)品定位、功能架構(gòu)與差異化優(yōu)勢(shì),避免開發(fā)過程中的方向性錯(cuò)誤。
- 創(chuàng)新概念與造型設(shè)計(jì)(ID):運(yùn)用創(chuàng)意與美學(xué)素養(yǎng),進(jìn)行多輪概念草圖、2D效果圖、3D建模與渲染,塑造產(chǎn)品的視覺識(shí)別與情感連接。
- 工程與結(jié)構(gòu)設(shè)計(jì):確保設(shè)計(jì)創(chuàng)意能夠轉(zhuǎn)化為可制造、可量產(chǎn)、符合成本與質(zhì)量要求的實(shí)體產(chǎn)品,涉及材料選擇、生產(chǎn)工藝、裝配方式等細(xì)節(jié)。
- 原型制作與測(cè)試:通過快速原型(如3D打印、CNC加工)制作功能樣機(jī),進(jìn)行實(shí)際測(cè)試與迭代,驗(yàn)證設(shè)計(jì)的可行性與用戶體驗(yàn)。
- 生產(chǎn)支持與供應(yīng)鏈協(xié)調(diào):協(xié)助客戶與制造商溝通,確保設(shè)計(jì)意圖在批量生產(chǎn)中得到準(zhǔn)確實(shí)現(xiàn),并可能參與包裝、標(biāo)識(shí)等延展設(shè)計(jì)。
2. 服務(wù)公司的典型類型與選擇
市場(chǎng)上的工業(yè)設(shè)計(jì)服務(wù)公司大致可分為幾類:
- 綜合性設(shè)計(jì)咨詢公司:提供從策略到生產(chǎn)的全流程服務(wù),團(tuán)隊(duì)規(guī)模較大,跨學(xué)科能力強(qiáng),適合大型企業(yè)或復(fù)雜產(chǎn)品項(xiàng)目。
- 專注于特定領(lǐng)域的工作室:如消費(fèi)電子、醫(yī)療設(shè)備、家居用品等,在垂直領(lǐng)域積累深厚,能提供更專業(yè)的行業(yè)洞察與技術(shù)解決方案。
- 自由設(shè)計(jì)師或小型團(tuán)隊(duì):靈活性高,溝通直接,成本相對(duì)較低,適合初創(chuàng)公司或中小型企業(yè)的初期項(xiàng)目與概念探索。
企業(yè)在選擇服務(wù)伙伴時(shí),應(yīng)重點(diǎn)考察其過往案例與自身行業(yè)的匹配度、設(shè)計(jì)流程的系統(tǒng)性、團(tuán)隊(duì)的綜合能力(特別是工程落地經(jīng)驗(yàn)),以及溝通協(xié)作的順暢程度。
3. 當(dāng)前趨勢(shì)與未來展望
隨著技術(shù)發(fā)展與市場(chǎng)變化,工業(yè)設(shè)計(jì)服務(wù)也在不斷演進(jìn):
- 數(shù)字化與智能化融合:物聯(lián)網(wǎng)(IoT)、人工智能(AI)的普及,要求設(shè)計(jì)不僅關(guān)注物理形態(tài),更需整合交互界面、數(shù)據(jù)可視化與智能服務(wù)體驗(yàn)。
- 可持續(xù)設(shè)計(jì)成為主流:從材料循環(huán)利用、節(jié)能設(shè)計(jì)到延長(zhǎng)產(chǎn)品生命周期,環(huán)保與社會(huì)責(zé)任已成為設(shè)計(jì)的重要考量。
- 服務(wù)設(shè)計(jì)思維擴(kuò)展:設(shè)計(jì)對(duì)象從單一產(chǎn)品擴(kuò)展到整體服務(wù)系統(tǒng),注重用戶旅程與觸點(diǎn)設(shè)計(jì),提升全鏈路體驗(yàn)。
- 敏捷設(shè)計(jì)與協(xié)同工具:遠(yuǎn)程協(xié)作軟件、云端渲染與仿真工具的應(yīng)用,提升了設(shè)計(jì)效率與全球團(tuán)隊(duì)的協(xié)同能力。
###
優(yōu)秀的工業(yè)設(shè)計(jì)服務(wù)公司,是企業(yè)創(chuàng)新的“外腦”與“合作伙伴”。它們通過專業(yè)的設(shè)計(jì)思維與方法論,不僅創(chuàng)造出美觀好用的產(chǎn)品,更幫助企業(yè)降低開發(fā)風(fēng)險(xiǎn)、縮短上市時(shí)間、提升品牌價(jià)值。在競(jìng)爭(zhēng)日益激烈的市場(chǎng)環(huán)境中,投資于專業(yè)的工業(yè)設(shè)計(jì)服務(wù),已不再是可選項(xiàng),而是打造成功產(chǎn)品的戰(zhàn)略性必需。對(duì)于尋求突破的企業(yè)而言,選擇一個(gè)理念契合、能力全面的設(shè)計(jì)服務(wù)伙伴,無疑是邁向成功的關(guān)鍵一步。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.debuild.com.cn/product/20.html
更新時(shí)間:2026-06-09 19:30:44