2021年上半年寧波服務外包業務運行情況分析 工業設計服務異軍突起
2021年上半年,在全球經濟逐步復蘇與中國經濟持續向好的大背景下,寧波市服務外包產業展現出強勁韌性與創新活力。作為服務外包領域的重要細分板塊,工業設計服務表現尤為亮眼,成為推動寧波產業轉型升級與價值鏈攀升的關鍵動力。本報告旨在對上半年寧波工業設計服務外包業務的運行情況進行梳理與分析。
一、 總體運行態勢:量質齊升,增長強勁
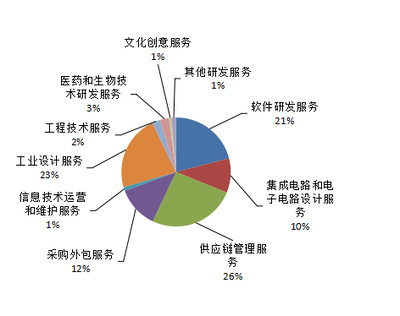
2021年1-6月,寧波市承接的工業設計類服務外包合同額與執行額均實現同比高速增長,增速顯著高于服務外包產業整體水平。這一方面得益于國際市場需求回暖,尤其是智能制造、消費電子、智能家居等領域的海外訂單持續釋放;另一方面,國內“雙循環”新發展格局的構建,以及“中國制造2025”與寧波“246”萬千億級產業集群建設的深入推進,為本地工業設計服務創造了龐大的內需市場。業務結構持續優化,從初期的簡單外觀設計,快速向涵蓋用戶體驗(UX)研究、產品結構設計、CMF(顏色、材料、工藝)設計乃至品牌策略整合的全流程、高附加值服務延伸。
二、 驅動因素分析
- 產業基礎與政策賦能:寧波雄厚的制造業基礎,特別是裝備制造、汽車零部件、家用電器等優勢產業,為工業設計提供了豐富的應用場景和需求源泉。市、區兩級政府出臺的關于促進服務外包及工業設計發展的專項扶持政策,在人才引進、市場開拓、平臺建設等方面提供了有力支持。
- 創新能力持續增強:一批本土工業設計企業(機構)快速發展,在設計理念、技術工具(如三維建模、仿真分析、虛擬現實)應用等方面不斷突破,設計成果轉化效率顯著提高。寧波積極引進國內外知名設計機構與高端人才,提升了行業整體競爭力。
- 數字化與外包模式演進:疫情加速了遠程協作與數字化交付的普及。寧波工業設計企業積極利用云設計平臺、協同軟件等工具,高效承接并交付離岸和在岸業務。服務外包模式也從單一項目委托,向長期戰略合作、聯合研發設計等更緊密模式發展。
三、 市場結構特點
- 離岸市場多元化鞏固:傳統主要市場如歐盟、美國、日本等保持穩定增長,對“一帶一路”沿線國家和地區的出口設計服務增速加快,市場多元化戰略成效顯現。離岸業務中,高技術含量、引領消費趨勢的設計需求占比不斷提升。
- 在岸市場成為壓艙石:服務于長三角及國內其他區域的工業設計業務量龐大且穩定。本土制造業企業對于通過卓越設計提升產品競爭力、塑造品牌價值的意識空前強烈,釋放了大量高端設計外包需求。
四、 面臨的挑戰與未來展望
挑戰主要包括:國際高端設計競爭加劇,復合型高端設計人才仍有缺口;知識產權保護與運營能力需進一步提升;產業鏈協同深度有待加強,設計與工程、制造、市場的銜接需更順暢。
隨著“十四五”規劃全面實施與寧波打造全球智造創新之都的推進,工業設計服務外包將迎來更廣闊空間。預計下半年及該領域將繼續保持快速增長,并向以下方向發展:
- 智能化與融合化:更深層次融合人工智能、大數據分析,實現設計流程智能化與個性化。
- 服務鏈條延伸:從產品設計向涵蓋市場研究、供應鏈設計、可持續設計的全生命周期服務拓展。
- 生態化集聚:依托寧波工業互聯網研究院、各類設計園區等平臺,形成更具影響力的工業設計創新生態圈。
2021年上半年,工業設計服務已成為寧波服務外包產業中增長迅猛、附加值高、帶動性強的明星領域。通過持續強化創新、深化國際合作、優化產業生態,寧波有望進一步鞏固和提升其在全球工業設計服務外包市場中的地位,為制造業高質量發展注入核心設計驅動力。
如若轉載,請注明出處:http://www.debuild.com.cn/product/29.html
更新時間:2026-06-07 22:37:33